深度表示学习在时序、图像与视频数据上的应用初探(Primary Applications of Deep Representation Learning in Time Series, Image and Video Data)
Shiqi Liu
The advent of the era of big data has brought about a drastic change in the basic model of machine learning. The traditional method of artificial feature extraction has been unable to meet the actual needs of diversified, complicated, and quantified application goals. Deep learning has gradually become the mainstream of applications due to its end-to-end data-driven adaptive feature extraction, which has attracted widespread attention in academia and industry. Based on the current research status, this article introduces representative deep learning methods for typical data types such as time series, images, and videos. Based on a deep understanding of the characteristics of the corresponding deep learning methods, it is applied to application problems such as hydrological time series processing, image factor learning, and emotional prediction of EEG data. The paper includes the following research contents.
First of all, we use the deep long short-term memory network (LSTM) to predict the daily runoff data of hydrological stations. Using the long short-term memory characteristics of LSTM, the deep LSTM achieves good results in Yichang Hydrological Station. We further compare the relative systematic error, relative standard deviation and relative error range of prediction results of LSTM and backpropagation neural network(BPNN) in flood season of Yi Chang, and the comparison results verify the superiority of the deep LSTM method over BPNN in predicting daily runoff in flood season. In order to verify the effectiveness of the proposed method, we compared the results of LSTM models and deep LSTM models on the data obtained from Cuntan, Wanxian, Fengjie and Yichang hydrological stations. The results show that both moels are suitable for daily runoff data, and deep LSTM models achieve better prediction results.
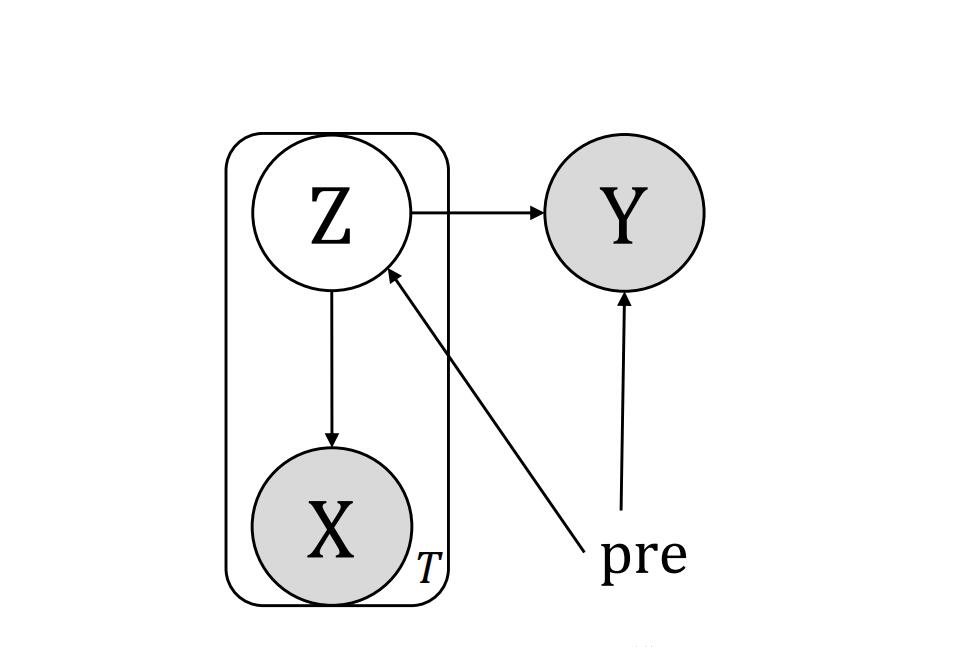
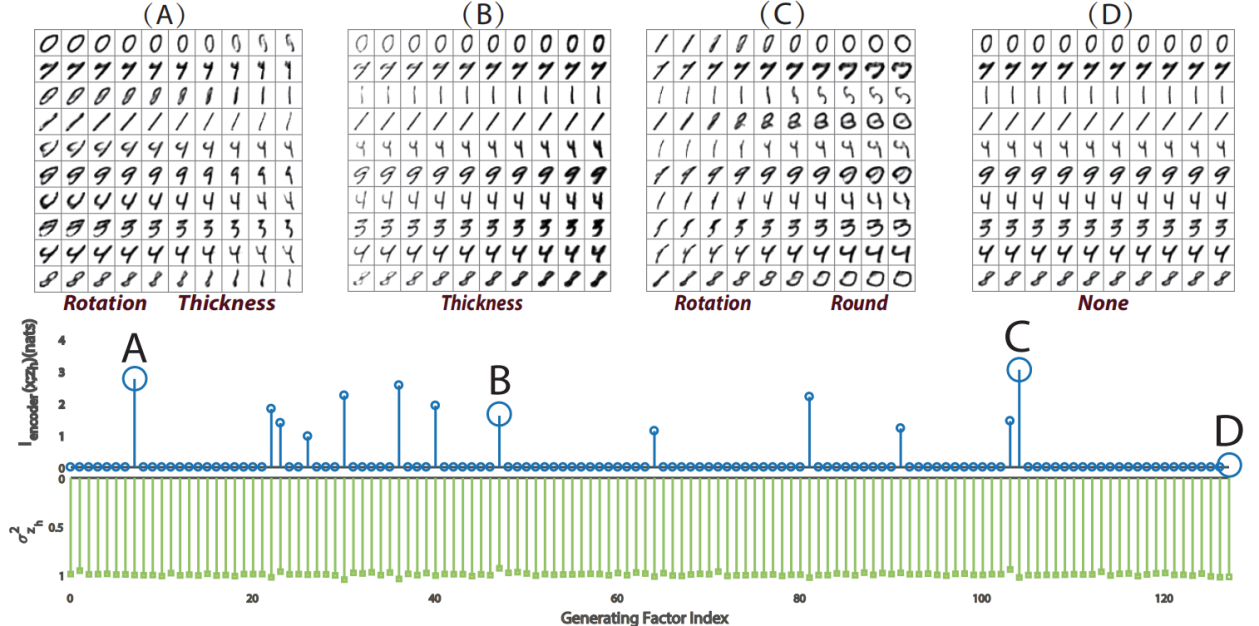
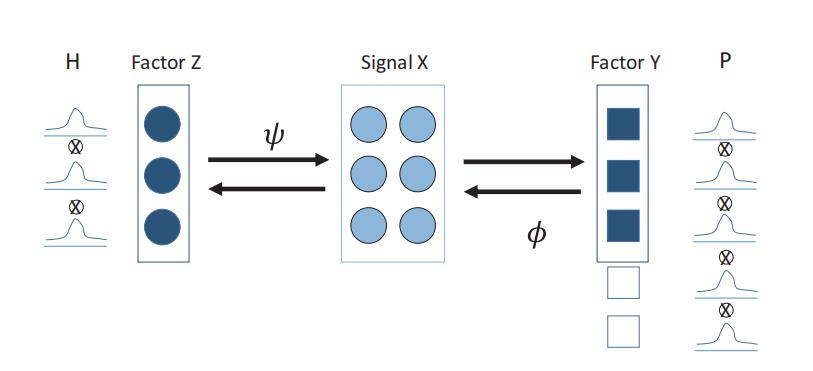
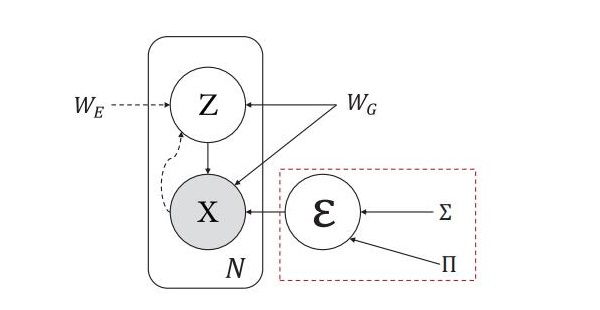
The second part is about one of the main models of deep representation learning, the variational autoencoder (VAE). We focus on supervising the factors extracted by VAE. VAE is used to learn the independent low-dimensional representation of images, but it faces the problem that some pre-specified factors are ignored. We assert that the mutual information of the input and each learned factor of the representation plays a necessary indicator to discover the influential factors. At the same time, we delve into the objective function of VAE, which shows that it tends to induce the sparsity of mutual information of factors when it exceeds the essential dimension of the data, resulting in some non-influential factors which can be ignored and which have negligible data reconstruction capabilities. We show that mutual information can affect the lower bound of VAE reconstruction errors and down-stream classification tasks. We propose an algorithm to calculate the mutual information indicator of VAE and prove its consistency. Experimental results on the MNIST, CelebA, and DEAP datasets show that mutual information helps determine influential generating factors. Besides some generation factors are interpretable, which can help down-stream generation and classification tasks. At last, we focus on deep representation learning applied to EEG video data emotion recognition. By characterizing the VAE and LSTM-based EEG emotion representation learning architecture, the method reaches the latest level. At the same time, the model can also monitor the learned feature shapes.
Summarizing the contents of the above three parts, the deep representation learning achieves good performance in time series, image, and video data and can reach the international frontier in some known application fields, such as hydrological prediction, image factor learning, and EEG emotion recognition. Therefore, this paper has significant research and application inspiration for the methodological expansion of these application fields and the methodological level of deep learning itself.

 Master
Master
 Bachelor
Bachelor
 Pattern Recognition
Pattern Recognition
 Openreview
Openreview
 Openreview
Openreview
 CIS
CIS
 Information Sciences
Information Sciences


 Geography Teaching
Geography Teaching